2 Das lineare Modell
Das lineare Modell ist die Basis von fast allem. Auch was Sie schon kennen, wird unter dem Konzept "lineares Modell" zusammengefasst:
- Varianzanalyse
- Korrelation
- Regression
Das lineare Modell ist auch nicht auf lineare Zusammenhänge beschränkt. Es kann sehr gut mit kurvilinearen Zusammenhängen umgehen. Also, wenn zum Beispiel bei einer Gesamtnachrichtenlage mit sehr hohem Nachrichtenwert der Umfang des Medienkonsums steigt. Irgendwann erfährt diese Wirkung einen Deckeneffekt, weil niemand auf Dauer 24h am Tag Medien konsumieren kann. Vielleicht steigt der Nachrichtenkonsum mit dem Nachrichtenwert sogar Anfangs exponentiell (wie Coronazahlen) und hat dann bald einen Umkehrpunkt und strebt gegen ein mögliches Maximum. Selbst solche komplexeren Zusammenhänge können in einem linearen Modell dargestellt werden.
Die höhere Statistik wie Faktorenanalysen, Strukturgleichungsmodelle, Zeitreihenanalysen (Forcastings oder Laten-Growth-Curve-Modelle) bauen alle auf dem linearen Modell auf. Und auch Computational Science nutzt Modelle und zwar überwiegend als Basis die linearen Modelle.
Welche der folgenden Analysemethoden gehören zum linearen Modell?
2.1 Varianzanalyse
Bei der Varianzanalyse werden Streuungen zerlegt. Das bedeutet, dass die Unterschiede zwischen den Fällen (z.B. Personen) in Bezug auf eine Variable (z.B. Links-Rechts-Spektrum) einen Mittelwert (Durchschnitt) haben und Abweichungen von diesem Mittelwert. Da die Abweichungen von einer Mitte negativ sind (links vom Mittel) und positiv sind (rechts vom Mittel) würde sich eine Summe aus allen Mittelwertabweichungen auf 0 aufaddieren -- darum ja eben auch Mittelwert, weil er in der Mitte liegt. Darum nehmen wir von den Mittelwertabweichungen immer das Quadrat. Die Quadrate (Minus * Minus = Plus und Plus * Plus = Plus) ergeben in der Summe einen positiven Wert und wenn man den durch die Anzahl n der Fälle teilt, dann hat man die Varianz. Anders gesagt: Die Varianz ist die durchschnittliche quadrierte Mittelwertabweichung (so steht's ja auch schon oben).
Bei der Varianzanalyse teilen wir unsere Stichprobe in Unterstichproben auf, also z.B. anhand von zwei Gruppen, wie Stadtbevölkerung und Landbevölkerung und schauen dann wo die Stadtbevölkerung im Mittelwert auf der Links-Rechts-Skala liegt und wo die Landbevölkerung im Mittel der Links-Rechts-Skala liegt. Mit hoher Sicherheit werden sich die Mittelwerte unterscheiden. Nimmt man nun die Varianz der Landbevölkerung um ihren Mittelwert und die Varianz der Stadtbevölkerung um ihren Mittelwert und addiert die zusammen, kommt ein kleinerer Wert heraus, als wenn man die Varianz für die Links-Rechts-Skala berechnet (nur wenn beide Mittelwerte identisch wären, wäre auch die Summe der Varianzen identisch), ohne die Unterscheidung zwischen Stadt und Land zu machen. Der Wert wird immer kleiner, je weiter die beiden Mittelwerte voneinander entfernt liegen. Wenn für die Links-Rechts-Skala die Summe der Varianzen der beiden Gruppen deutlich kleiner ist als die Gesamtvarianz, dann hat die Unterscheidung zwischen Stadt- und Landbevölkerung Varianz "aufgeklärt". Das ist Varianzaufklärung und die Basis der Varianzanalyse. Es geht kurz gesagt darum, ob die Unterschiede in einer Variable gross sind, weil sie durch eine andere Variable bedingt werden, für die die Varianz zerlegt wird. Darum sagt man auch "Varianzzerlegung". Wir werden uns das noch ausführlich bis genüsslich anschauen in diesem Semester.
Hier können Sie mit einer kleinen Onlineapp mit einer ANOVA (ANalysis Of VAriance) interaktiv herumprobieren:

Nun stellen Sie sich vor, Sie machen eine Auswertung und haben eine Variable die Sie erklären wollen, also eine abhängige Variable (AV), wie z.B. die Verweildauer auf TikTok-Videos. Die erklären Sie damit, wie viel Spass jemand an einem gezeigten Video hat. Sie könnten den Spass einteilen in "kein Spass", "wenig Spass" und "viel Spass". Dann könnten Sie für die drei Gruppen eine Varianzanalyse rechnen, testen Ihre Hypothesen mit t-Tests oder einer One-Way-Anova und kommen anhand der t-Werte oder auch F-Werte zu einer Entscheidung über statistische Hypothese: Der Zusammenhang ist signifikant oder nicht. Ok. -- Wenn das "lineare Modell" Varianzanalyse ist und Regression, dann müsste man doch dieselbe Analyse mit einer Regression machen können. Und ja, das kann man. Und es kommen ganz genau dieselben Ergebnisse raus: Dieselben t-Werte, dieselben F-Werte und natürlich, darauf fussend, dieselben p-Werte (Wahrscheinlichkeit, dass die t- und F-Werte zustandekommen, obwohl die Nullhypothese gilt). Wir probieren das mal: Und es wäre extrem peinlich für mich, wenn da unterschiedliche Werte rauskommen -- aufregend!
In R kann man mit Extrapaketen auch Varianzanalysen machen. Es gibt aber keine Pakete für Regressionen. Das liegt daran, dass das lineare Modell (lm) in R die Regression ist! Wir werden uns im ersten Teil des Moduls also mit dem linearen Modell auseinandersetzen.
2.2 Regression
Die Regression ist das einfachste und gleichzeitig mächtigste Werkzeug multivariater Datenanalyse. Aus den Kovarianzen mehrerer Variablen wird eine Funktion mit wenigen Kennwerten berechnet. Diese Kennwerte als Einzelwerte geben Auskunft über die Zusammenhänge zwischen einzelnen Prädiktoren und einer abhängigen Variablen. Man muss also vorher sagen, was man erklären will und womit man es erklären will. Die zu erklärende Grösse nennt man in der Sozialwissenschaft (und anderen Disziplinen): abhängige Variable (AV oder DV) und die Erklärungsgrössen nennt man: unabhängige Variablen (UV oder IV).
Die Regression baut auf Kovarianzen auf (bzw. Korrelationen, die wir uns besser vorstellen können). Die Regressionsgerade wird bei einer bivariaten Regression durch eine Konstante (in der Abbildung 2.1 ist sie 1) und einem Anstieg je Variable gekennzeichnet (in der Abbildung ist es 0,5 für die eine UV = x).
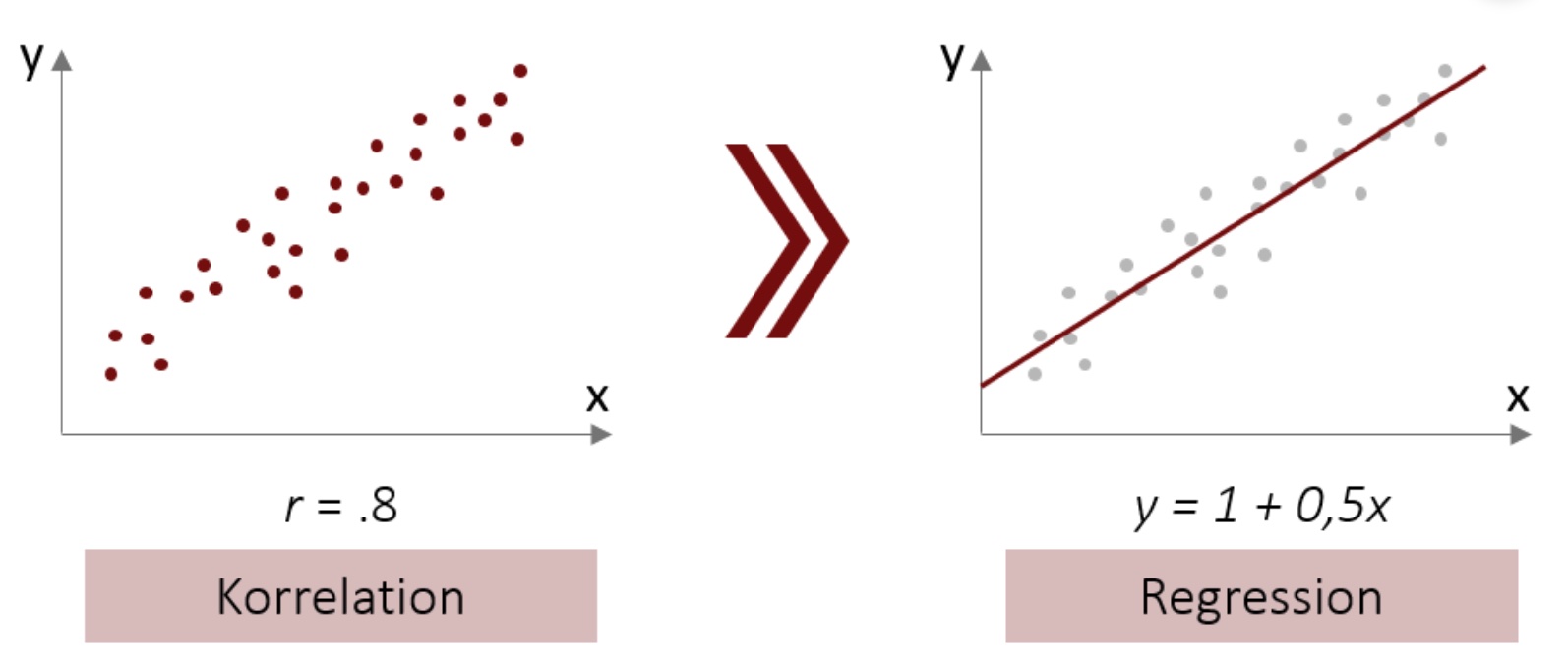
Abbildung 2.1: Von der Korrelation zur Regression
Das bedeutet, dass bei einer bivariaten Regression zwei b's die Lage der Regressionsgeraden bestimmen: Das ist zum einen die Konstante \(b_1\) und zum anderen der Anstieg \(b_2\) für die Gerade. In der Abbildung 2.2 sehen Sie links zwei Regressionsgeraden mit unterschiedlichen \(b_2\) (rot positiv und grün negativ). Auf der rechten Seite sehen Sie drei Regressionsgeraden mit unterschiedlichen \(b_1\), wobei das b der roten Gerade am grössten ist (knapp 70), grün am kleinsten (bischen über 20) und blau in der Mitte liegt (knapp 40).
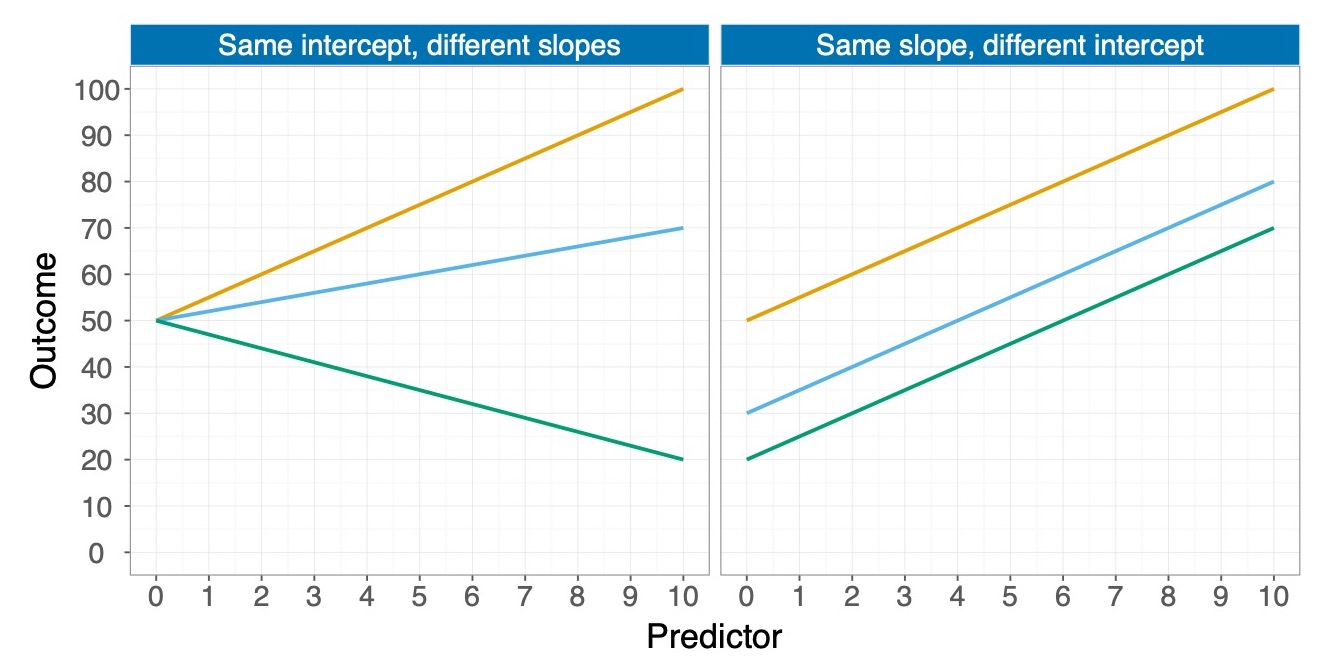
Abbildung 2.2: B's bei bivariaten Regressionen
Welche Funktion und Eigenschaften haben die Regressionskoeffizienten b?
2.2.1 Das Modell und die Regressionsgleichung als Schätzung
Die formelle Schreibweise eines Regressionsmodells enthält griechische Buchstaben um zu signalisieren, dass es sich hier um unbekannte Grössen, die Parameter in der Grundgesamtheit, handelt. So lange wir über die Qualität und die Eigenschaften von Regressionsrechnungen sprechen, wird uns der Unterschied zwischen \(\beta\)'s und b's interessieren.
Als Gleichung heisst das, dass die Abhängige Variable \(Y_i\) durch eine gewichtete Summe (siehe Formel (2.1)) von einer oder mehreren unabhängigen Variablen erklärt wird. Diese UVs werden in der Regel mit X gekennzeichnet und weil es mehrere davon geben kann, werden sie durchnummeriert. Also mit dem Subscript i für das Durchzählen werden sie griechisch für die Parameter als \(\beta_2X_{i2}\) bezeichnet oder eben als \(\beta_3X_{i3}\) usw. Dann gibt es noch den Rest \(U_i\). Das ist also das theoretische statistische Modell, dessen Parameter wir mit Kennwerten schätzen wollen.
\[\begin{align} Y_i&=\beta_1 + \beta_2X_{i2} + \beta_3X_{i3} + U_i \tag{2.1} \end{align}\]
Wenn man mal genau schaut was hier eigentlich noch variabel ist, nach der Stichprobenziehung, dann wird klar, dass die \(Y_i\) ja in der Datenerhebung gemessen wurden und damit Werte enthalten, die wir statistisch nicht mehr ändern. Das Gleiche gilt für die \(X_i\)-Werte der Variablen \(X_2\) und \(X_3\). Also sind diese Grössen eigentlich keine "Variablen" mehr, sondern längst durch echte Werte fixiert. Zu schätzen sind nur die Bs, also \(b_1\), \(b_2\) und \(b_3\) (übrigens nummerieren wir die so durch, weil sie später als Vektor in der Matrizenrechnung die erste Zeile belegen, die zweite und dritte usw.). Wenn wir die Regressionskoeffizienten, die b's in unserer Stichprobe, berechnet haben, müssen wir uns noch fragen, wie gut, also unverzerrt und genau sie die unbekannten Parameter (\(\beta\)s) messen, also -- etwas technischer ausgedrückt -- ob die b die \(\beta\) erwartungstreu und effizient schätzen. Dafür gibt es einige Voraussetzungen, die wir uns später [in Kapitel noch nicht da] noch anschauen werden. Am Ende der Formel steht das \(e_i\) für die Fehler, also den unerklärten Rest der Varianz, der zwischen den durch das Modell geschätzten Werten (gekennzeichnet mit einem Dach als \(\hat{Y_i}\)) und den gemessenen Werten liegt. Während die s's die Schätzer für die \(\beta\)s sind, ist das \(e_i\) kein Schätzer für \(U_i\). Das liegt daran, dass das \(e_i\) nur eine Fehlerstreuung in der Stichprobe ist und \(U_i\) viel mehr angibt, dass unberücksichtigte Einflussgrössen und ein stochastischer Rest nicht vom Modell abgebildet sind.
\[\begin{align} Y_i&=b_1 + b_2X_{i2} + b_3X_{i3}+e_i \end{align}\]
Bei einer Regression mit zwei UVs wird praktisch eine Ebene in die Punktwolke gelegt (siehe 2.3). Wir schätzen aber eine multivariate Regression, damit wir bivariat interpretieren können, also je UV sagen, wie stark der Effekt auf die AV ist. Insofern interpretieren wir je Variable nur ein b oder ein (BETA), was dem Ansteig (Zusammenhang) einer Variablen entspricht. Das können wir machen, weil die Statistik bzw. unser Statistikprogramm für uns die Kontrolle der übrigen Variablen übernimmt und wir schön die kontrollierte bivariate Beziehung interpretieren können. Die b's beschreiben dabei die Gerade, die die Ebene an der Stelle bildet, die für die andere Variable der Durchschnitt ist. Bei drei UVs spannen die b's zusammen eigentlich einen Raum auf, was sich aber niemand mehr visuell vorstellen kann. Die Statistik kann das aber und erledigt das so für uns, dass wir uns immer nur die Beziehungen anhand der jeweiligen b's der einzelnen UV's anschauen können.
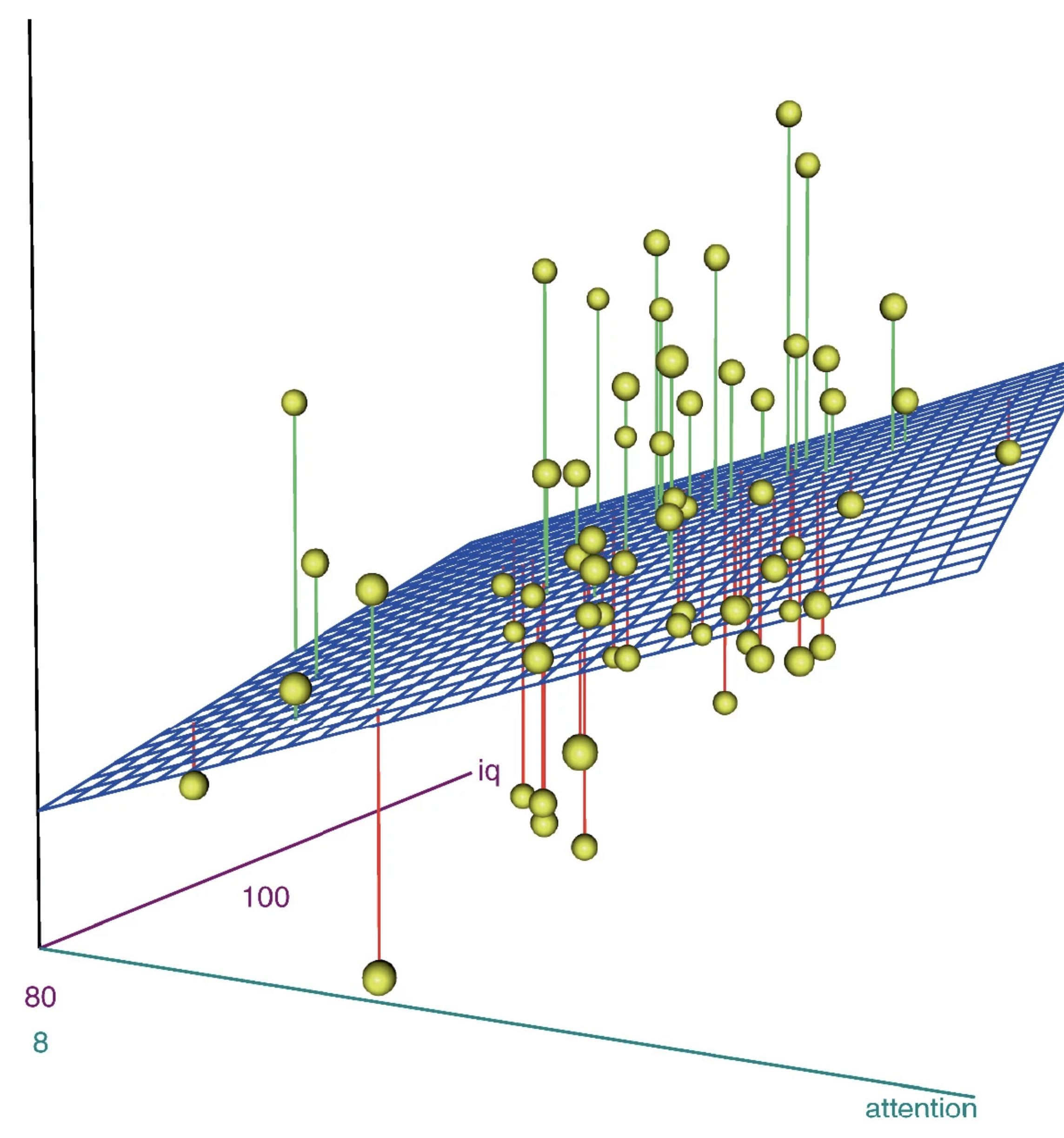
Abbildung 2.3: R-Quadrat
Hier wird eine Regression recht gut als Punktwolke visualisiert: http://shiny.calpoly.sh/3d_regression/.

Schreiben Sie die Formel für die einfache bivariate Regression auf?
\[\begin{align} Y_i&=b_1 + b_2X_{i2} +e_i \end{align}\]
2.2.2 OLS
Eine der einfacheren und grundlegenden Methoden um die b's zu bestimmen ist die Methode der kleinsten Quadrate bzw. OLS, was das Akronym für Ordinary Least Squares ist. Mit dieser Methode legt die Mathematik eine Gerade in eine Punktwolke, weil sie es nicht visuell und intuitiv machen kann. Das Prinzip ist recht einfach: Man versucht b's zu finden, für die die Fehler möglichst klein sind. Das ist im Grunde die Optimierungsaufgabe der OLS-Methode. Genau das machen wir auch, wenn wir eine Gerade in eine Punktwolke legen, wir bauen sie so ein, dass sie "optimal reinpasst" also die Abstände zu den einzelnen Punkten minimal sind.
Sehr gut hier zum anschauen und spielen:

Als Beispiel hatte ich in der Vorlesung gebracht, dass man auch mal überlegen könnte, welcher Wert eine Verteilung einer Variablen optimal repräsentieren würde. Wenn wir dieses Optimierungsproblem an OLS übergeben würden, dann würden wir sagen: Suche einen Wert a aus allen möglichen a-Werten, der für eine Variable x die kleinsten quadrierten Abstände hat. Damit es OLS versteht würden wir schreiben: \(\text{OLS bitte minimiere folgende Gleichung:} \sum_i{(x_i-a)^2}\)
Jetzt wissen wir, dass die quadrierten Abweichungen gross sein müssen, wenn a links vom Optimum liegt und immer kleiner wird, wenn wir uns dem optimalen a-Wert annähern. Dann wird die Summe der quadratischen Abstände wieder grösser. Also haben wir eine Funktion, die einer quadratischen Funktion folgt (dass die so aussieht, müssen wir garnicht wissen, aber es hilft vielleicht der Vorstellung). Wenn wir wissen wollen, wo diese Funktion ihr Minimum hat, dann können wir die Funktion ableiten und dann nach der Nullstelle der abgeleiteten Funktion suchen. An der Stelle liegt dann der a-Wert, der die Streuung einer jeden Variablen optimal abbildet, weil wir diese Ableitung völlig abstrakt und ohne konkrete Werte gemacht haben und sie daher immer gilt. Also:
\[\begin{align} \frac{df}{da} = & \sum_i{(x_i-a)^2}^{\prime} = 0 \tag{2.2}\\ 0 = & \sum_i{[x_i^2 - 2x_ia + a^2]}^{\prime} \tag{2.3} \end{align}\]
In der ersten Zeile das df/da bedeutet, dass abgeleitet (differenziert) werden soll und zwar die Funktion f nach a. In der zweiten Zeile sehen wir dann schon die Ableitung nach Ableitungsregeln (wer extrem Bock hat, kann sich die ja nochmal angucken) und gleich auch schon mit 0 gleichgesetzt.
In der nächsten Zeile (2.4) wird ein bischen aufgelöst und umgestellt (müssen Sie nicht können).
\[\begin{align} 0 = & -2\sum_i{x_i} + 2na & |:2n\ |+\sum_i{x_i} \tag{2.4}\\ \frac{\sum_i{x_i}}{n} = & a \tag{2.5} \\ a = &\overline{x} \tag{2.6} \end{align}\]
Am Ende kommt als Lösung für den nach OLS besten Repräsentanten einer Variablen heraus: \(\frac{\sum_i{x_i}}{n} = a\) (2.5). Der linke Teil ist genau die Definition von \(\overline{x}\), also dem Mittelwert. Damit haben wir mit einer Ableitungen der OLS herausgefunden, dass der Mittelwert die kleinste Summe der quadrierten Abstände jedes Wertes zu einem Wert a hat, also der gesuchte beste Repräsentant für eine Variable der Wert \(a=\overline{x}\) ist (2.6). Dasselbe könnten wir für die Formel \(Y_i = b_1 + b_2X_i + e_i\) machen. Wenn wir (mit ein paar Annahmen) das für jedes \(b_1\) bis \(b_3\) machen würden, dann hätten wir die b's mit OLS bestimmt. Da das ungleich komplizierter ist als für den Mittelwert, schlage ich vor, wir lassen das an dieser Stelle.
Ich habe Ihnen eine Excel-Datei gebaut, mit der Sie sich das Prinzip von OLS interaktiv anschauen können:

Welche Funktion und Eigenschaften hat OLS
2.2.3 B's
Wenn wir mit Hilfe der OLS-Methode eine Formel für die b's gesucht haben, kommt folgende Formel (2.7) für das \(b_2\) der Variable \(x_2\) heraus :
\[\begin{align} b_2 = \frac{r_{y2}-r_{23}r_{y3}}{(1-r_{23}^2)}\frac{s_y}{s_2} \tag{2.7} \end{align}\]
Die Formel hat es in sich. Aber schauen Sie sich die Formel mal ganz in Ruhe und stückchenweise an. Als eines der ersten Elemente taucht \(r_{y2}\) auf, was so viel heisst, wie die einfache Korrelation zwischen y und der ersten x-Variable, die ja das \(b_2\) hat und darum kurz und knapp nur noch mit dem Subscript 2 bedacht wird. Also hängt das b mit der Korrelation zwischen der zugehörigen x-Variable und y zusammen. Da b skalenabhängig ist und r nicht, steht hinten noch dieses \(\frac{S_y}{S_2}\). Dieser Termin sorgt nur dafür, dass b in der Skala von y angegeben ist (darum auch multipliziert mit \(s_y\)) -- den Teil können Sie schon mal vergessen. Interessanter ist der zweite Teil der Gleichung über dem Bruchstrich: Wir ziehen da das Produkt aus \(r_{23}\) und \(r_{y3}\) ab. Das heisst, wir gehen von der bivariaten Korrelation aus, rechnen jetzt aber noch die Korrelation raus, die die beiden unabhängigen Variablen \(x_2\) und \(x_3\) untereinander haben. Wir ziehen allerdings nicht einfach \(r_{23}\) ab, sondern multiplizieren das auch noch mit \(r_{y3}\). Das bedeutet, wir haben einen Zusammenhang \(r_{y2}\) und rechnen aus dem den Anteil gemeinsamer Varianz, also der Zusammenhänge der Varialbe \(x_2\) heraus, die diese mit \(x_3\), wobei wir nur so viel rausrechnen, wie die dritte Variable \(x_3\) wiederum mit y gemeinsam hat. Wären die beiden Variablen \(x_2\) und \(x_3\) unkorrelliert, dann wäre auch das Produkt \(r_{23}r_{y3} = 0\), weil \(0 \cdot r_{y3} = 0\). Wenn \(x_2\) und \(x_3\) korrellieren, aber \(x_3\) und y nicht, dann würden wir auch nichts von \(r_{y2}\) abziehen. Im Storchenbeispiel würden wir also sagen, wir sehen den Zusammenhang zwischen Geburtenrate und Anzahl Störche. Wir müssen aber aus dieser Korrelation herausrechnen, dass die Drittvariable (\(x_3\)) Bevölkerungsdichte (Stadt vs. Land) stark mit der Geburtenrate korrelliert und mit der Anzahl der Störche, die in einer Region leben.
2.2.4 Das Bestimttheitsmass \(R^2\)
Das Bestimmtheitsmass gibt an, wie gut die Werte der AV durch die Werte der UV vorhergesagt werden können.
Wie viel von der Varianz der AV durch ein Modell aufgeklärt werden kann, stellt man fest, indem zunächst die Summe der quadrierten Abweichungen (Sum of Squares) für alle \(Y_i\) Werte gezählt werden. Also die totale Varianz der AV, die geschrieben wird als \(SS_T\) (Sum of Squares Total). Jetzt ist die Frage, wie viel von dieser Sum of Squares Total durch die Sum of Squares des Modells (\(SS_M\)) erklärt werden kann. Darum setzen wir diese beiden Summen der Quadrate (wenn man jeweils durch n teilen würde, wären das die Varianzen) ins Verhältnis zueinander und bekommen einen Prozentwert. Also rechnen wir \(\frac{SS_M}{SS_T}\) und bekommen einen Wert zwischen 0 und 1 bzw. 0% und 100% (% heisst ja "von Hundert" bzw. "geteilt durch 100"). Das ist der aufgeklärte Varianzanteil und den nennen wir \(R^2\).
- \(SS_T\): Summe der quadrierten Abweichungen für die AV (Y).
- \(SS_M\): Summe der quadrierten Abweichungen des Modells (der Punkte auf der Geraden, bzw. die geschätzten \(\hat{Y_i}\)-Werte).
Also: \(R^2 = \frac{SS_M}{SS_T}\)
Bei dieser Formel (2.8) können wir durch n teilen, also über und unter dem Bruch \(1/n\) ergänzen und hätten:
\[\begin{align} R^2 = \frac{SS_M/n}{SS_T/n} \tag{2.8} \end{align}\]
Was in Worten ausgedrückt bedeutet:
\[\begin{align} R^2 = \frac{\text{aufgeklärte Varianz}}{\text{Gesamtvarianz}} \tag{2.9} \end{align}\]
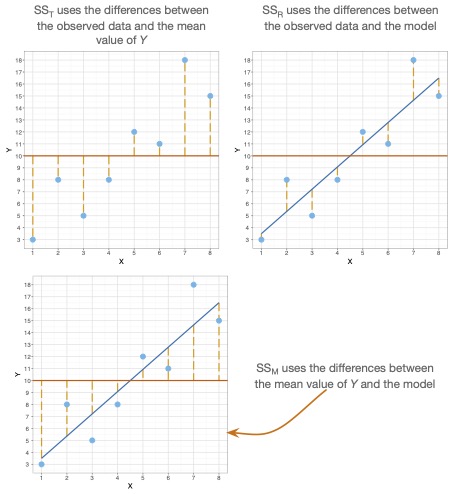
Abbildung 2.4: R-Quadrat
Mit dem Bestimmtheitsmass können wir angeben, wie gut ein Modell insgesamt ist. Wir werden später noch diskutieren, wie sinnvoll das ist. Spoiler: Nicht immer sehr sinnvoll, weil \(R^2\) eigentlich mehr eine Stichprobeneigenschaft ist und wenig über die Welt sagt und recht einfach hochgeschraubt werden kann, indem man triviale und langweilige Variablen in ein Modell einbaut.
Was wissen Sie über das Bestimmtheitsmass \(R^2\)?




2.3 Vorraussetzung für BLUE
Damit unsere b's aus der OLS die besten linearen unverzerrten Schätzer (BLUE:Best Linear Unbiased Estimator) für die \(\beta\)s sind, müssen ein paar Voraussetzungen erfüllt sein. Diese Voraussetzungen gucken wir uns in diesem Kapitel an. Zusammengefasst sind es:
V1. Die UVs und die AV dürfen keine Konstanten sein.
V2. Das Skalenniveau der UVs muss metrisch oder dichotom (0/1) sein.
V3. Die Werte der X müssen fix sein.
V4. Das Modell muss voll spezifiziert sein. D.h.: Keine Korrelation mit externen Variablen.
V5. Es darf keine perfekte oder heftige Multikollinearität geben.
V6. Die Residuen müssen bei jedem Wert jeder UV gleich streuen (Homoskedastizität).
V7. Die Residuen müssen grob normalverteilt sein.
V8. Die Residuen dürfen nicht autokorreliert sein.
Was verbirgt sich hinter demm Akronym BLUE (ausgeschrieben)?
Best Linear Unbiased Estimator
2.3.1 Variablenskalierung (V1.-V2.)
Die beiden ersten Voraussetzungen (V1. und V2.) betreffen die Skalierung der Variablen.
2.3.1.1 Variablen dürfen keine Konstanten sein (V1.)
Die UVs und die AV dürfen keine Konstante sein. Das ist insofern recht trivial, als dass eine Konstante mit nichts kovariieren kann, weil Konstanten nicht variieren. Je grösser "\(\pi\), desto \(...\)" macht einfach keinen Sinn. Da Konstanten nicht variieren (keine Varianz haben), können sie nicht kovariieren und können daher in keinen Erklärungsmodellen als Variablen einbezogen werden. An dieser Stelle klingt das sehr trivial. Und doch kommt es immer wieder vor, dass in Hypothesen Variablen einfliessen, die in der gewählten Stichprobe konstant sind. Zum Beispiel ist in der Hypothese "Wenn über Sport berichtet wird, zählen Superlative besonders." Das Konstrukt "über Sport berichtet" ist eine Konstante, wenn nur der Sportteil untersucht werden soll. Hypothesen sind keine Annahmen über Zusammenhänge mehr, wenn eines der Konstrukte, die in Hypothesen zusammengebracht werden, in den Daten eine Konstante ist. Oftmals kommen solche Hypothesen mit Konstanten zustande, wenn der Fokus auf eine Ausprägung einer Variablen gelegt wird und die Abweichung von dieser Ausprägung nicht erhoben wird. Annahmen über den Wandel von Kriegsberichterstattung kann als zeitlicher Prozess nicht untersucht werden, wenn nur das Heute untersucht wird. Oft genug kommen Konstanten in Hypothesen vor, wenn das Forschungsinteresse aus dem Interesse der Forschenden eigentlich deskriptiv ist, also nur die Verteilung von einzelnen Variablen gefragt ist, und dann posthoc Hypothesen formuliert werden sollen, weil das von den Dozierenden oder Reviewern verlangt bzw. erwartet wird. ;-)
2.3.1.2 Variablen sollen metrisch sein (V2.)
Die AV und die UVs sollen metrisch sein. Das klingt nach einer recht harten Voraussetzung. Allerdings gibt es die schöne Eigenschaft von Dummyvariablen (0/1), dass sie sich verhalten wie metrische Variablen, weil ihr Mittelwert und ihre Streuung sinnvoll interpretierbar sind. Dummyvariablen können also gut als UVs eingesetzt werden. Nun ist diese spezielle Form der dichotomen Variable (zwei Ausprägungen) nur die eine Form der nominalen Variablen. Dichotome Variablen können immer als Dummyvariable dargestellt werden. Man muss ja nur eine Ausprägung in 0 umkodieren und die andere in 1. Bei den kategorialen Variablen gibt es mehr Ausprägungen. Zum Beispiel Gender mit 1 = weiblich, 2 = männlich, 3 = divers2. Das Gute wiederum ist, dass kategoriale Variablen vollständig mit Dummyvariablen abgebildet werden können. Das geht dann so: Man baut eine Variable "Weiblich", die die Ausprägungen 1 = "trifft zu" und 0 = "trifft nicht zu" hat. Dann gibt es eine zweite Variable für "männlich" mit 0 und 1 und auch eine Dummy für "Divers". Diesem Vorgehen sind eigentlich keine Grenzen gesetzt. Man könnte also auch noch erweitern oder differenzieren in "transgender", "genderqueer", "genderfluid", "bigender", "pangender", "trigender", "agender", "demigender", "abinär" und zur Sicherheit in Deutschland auch "Taucher"3.
In den linearen Modellen können Sie also auch kategoriale Variablen einbauen4. Auch die AV kann eine Dummyvariable sein. Das führt allerdings zu ein paar Problemen mit dem einfachen linearen Modell. Deshalb werden bei einer AV mit nur den Ausprägungen 0 und 1 logistische Regressionen gerechnet. Damit befassen wir uns später. Es geht auch, dass die AV kategorial ist. Das ist dann so ähnlich wie mit den Dummys als UV, weil dann mehrere Regressionen mit mehreren Dummys für die AV gerechnet werden. Das wird multinominale Regression genannt (auch bekannt als Diskriminanzanalyse).
Dann bleiben im Grunde nur die ordinalen Variablen übrig, die mehr Informationen über Ordnung der Ausprägungen (Rangordnung) enthalten, aber die Zahlenwerte (numerisches Relativ) mit ihren identischen Abständen (1 zu 2 wie 2 zu 3 und 3 zu 4 usw.) nicht abbilden, dass die Abstände der gemessenen Ausrägungen (empirisches Relativ) nicht annähernd gleich sind (1 = "arm", zwei = "reich", 3 gleich "superreich"). Dafür gibt es drei Lösungen, um ordinale Variablen auch in lineare Modelle einbeziehen zu können.
Ordinale Variablen werden als metrisch oder quasimetrisch behandelt und wie metrische in ein Modell aufgenommen. Das geschieht praktisch häufig, wenn z.B. Schulnoten einfach in ein lineares Modell aufgenommen werden. Wir wissen, dass die Abstände zwischen der Schweizer Bestnote 6.0 und 5.5 nicht genauso gross sind, wie zwischen 5.5 und 5.0 oder gar 4.0 und 3.5. Dennoch sind die Schätzer der linearen Modelle relativ robust gegen diese Verletzung. Gerade wenn es eigentlich nur darum geht, zu prüfen, ob Schulnoten einen signifikanten Effekt auf eine AV haben, dann kann man diese ordinalen Variablen getrost als "quasimetrisch" verwenden. In diesen Fällen sollte man nur etwas vorsichtiger sein, wenn eine Signifikanzschwelle nur knapp gerissen wurde oder b als Effekt nur knapp die Schwelle der Interpretierbarkeit übersprungen hat, dann sollte man bescheiden sein und klar machen, dass aufgrund der Datenlage und dem Skalennivau der Variablen die Zahlen nicht überinterpretiert werden sollten.
Es gibt auch die Möglichkeit, ordinale Variablen als kategoriale Variablen zu behandeln (womit ihr Datenniveau aber eigentlich herabgestuft wird). Dann würden wir die Ausprägungen der ordinalen UVs wiederum in Dummyvariablen umkodieren und nur die Dummys interpretieren. Im besten Fall werden in solche Interpretationen die zugrundeliegende Rangfolge der Dummys berücksichtigt, also die erste Gruppe mit der zweiten, die zweite mit der Dritten und dann die erste mit der Dritten, aber mit Rücksicht auf die Bedeutung der Rangfolge.
Wenn eine oder mehrere UVs klar ordinal sind, also die Abstände zwischen den Zahlenwerte deutlich auseinandergehen oder vielleicht sogar variieren (Laufwettkampf mit mal sehr knappen Unterschieden und mal sehr grossen von Platz eins zu Platz zwei, wenn Kipchoge mitläuft), dann sollten die ordinalen nicht einfach als metrische betrachtet werden. Wenn solche ordinalen Variablen zentral sind, dann kann auch nicht einfach auf Dummys ausgewichen werden. Dafür gibt es aber inzwischen Analysemethoden der ordinalen Regression, die in diesen Fällen eingesetzt werden können. Mit dem Verständnis der normalen linearen Modelle ist es nicht mehr schwer, sich so gut selbständig in die ordinale Regression einzuarbeiten, dass sie gewinnbringend eingesetzt werden kann.
2.3.2 Modellspezifikation und Multikollinearität (V3.-V5.)
2.3.2.1 V3. Fixe X
Dass die UVs fix sein sollen, bedeutet im Grunde nur, dass sich die UVs nicht ständig ändern sollen, sondern in unserer Auswahlgesamtheit stabil sind. Wenn sich zum Beispiel die Berichterstattung insgesamt häufig stark ändert, dann wäre es nicht gut, wenn wir mit der Stichprobe einer Inhaltsanalyse arbeiten, die in einer sehr speziellen Zeit erhoben wurde (z.B. ein Kriegsanfang). Diese Stichprobe in einer Spezialzeit würde zu verzerrt geschätzten B's in der Normalzeit führen (vgl. Wolling 2015). Da wir nicht davon ausgehen können und wollen, dass unsere Theorien in der Sozialwissenschaft immer und ewig gelten, verlangen wir nur mittelfristig gültige Theorien ("middle range theory" (Merton 2012)) und dass unsere Variablen mittelfristig relativ stabil bzw. fix sind. Das bedeutet insbesondere, dass wir bei der Stichprobenziehung aufpassen müssen, dass wir nicht eine sehr spezielle Stichprobe in einer ganz besonderen Phase erheben, die Effekte hat, die sonst sehr untypisch sind. Das ist das, was mit fixe X gemeint ist.
2.3.2.2 V4. Voll spezifizierte Modelle
Unsere B's sind nur dann unverzerrt, wenn das Modell voll spezifiziert ist in Bezug auf Einflüsse, die mit unseren B's in Wirklichkeit zusammenhängen. Wenn wir vergessen in unsere Überlegungen und Messungen einzubeziehen, dass die Storchenpopulation einer Gegend nur darum mit der Geburtenrate zu tun hat, weil in ländlichen Regionen die Geburtenrate höher ist und mehr Störche leben als in der Stadt; wenn wir also diesen Dritteinfluss vergessen, dann scheint es einen Zusammenhang zwischen Geburtenrate und Storchenpopulation zu geben. Wir würden falsche Schlüsse ziehen, weil der Zusammenhang verzerrt geschätzt würde. Journalistinnen vom Berliner Kurier könnten glauben, dass der Storch die Kinder bringt. Wir müssen also theoretisch erarbeiten, welche Einflüsse von Bedeutung sein könnten für unsere AV oder den Zusammenhang zwischen den UVs und der AV beeinflussen könnten. Das ist Theoriearbeit. Dieser Zusammenhang muss sich auch mathematisch in der Statistik abbilden, was er auch tut.
Wenn wir mal annehmen, dass die wahren Zusammenhänge gut durch die Formel (2.10) dargestellt wären, aber die Theorie zu dem Thema auf dem Stand ist, dass die einfacheren Zusammenhänge aus der Formel (2.11) gelten, also eine wichtige Einflussgrösse (\(X_4\)) nicht berücksichtigt wurde. Wenn dem so wäre, dann würde das Unbekannte (\(U_i\)) in Formel (2.11) nicht nur den einfachen stochastischen Rest umfassen, sondern zusätzlich \(\beta_4X_{i4}\). Dann wäre der Erwartungswert (also der Wert, um den unsere Stichprobenparameter b streuen) nicht mehr das erhoffte \(\beta_2\) sondern \(\beta_2 + \beta_4b_{42}\), wie in Formel (2.12). Das würde zu einem Fehler führen, der bei \(\frac{r_{42}-r_{32}r_{43}}{1-r^2_{32}}\sqrt{\frac{V_4}{V_2}}\) liegt. Wenn wir also ewig Stichproben ziehen würden und jedes Mal ein \(b_2\) bestimmen würden, dann würden diese \(b_2\)s nicht um \(\beta_2\) streuen. Das Mass, um das wir uns verschätzen würden, wäre so gross wie in (2.13) notiert. Auch unsere Signifikanztests wären falsch und die Konfidenzintervalle würden an der falschen Stelle liegen. Unsere ganze Analyse wäre falsch.
\[\begin{align} \text{wahr:} Y_i=&\beta_1 + \beta_2X_{i2} + \beta_3X_{i3} + \beta_4X_{i4}+U_i \tag{2.10}\\ \text{geschätzt: } Y_i=&\beta_1 + \beta_2X_{i2} + \beta_3X_{i3} +U^\star_i \text{\qquad wobei \quad } U^\star_i = \beta_4X_{i4}+U_i \tag{2.11}\\ \text{also: } E(b_2) =& \beta_2 + \beta_4b_{42} \tag{2.12}\\ \text{mit: } b_{42}=&\frac{r_{42}-r_{32}r_{43}}{1-r^2_{32}}\sqrt{\frac{V_4}{V_2}} \tag{2.13} \end{align}\]
Wie geht man nun mit dieser Tyrannei um, dass man alle Einflüsse kennen sollte, die schlicht unbekannt sind. Nur Chuck Norris weiss, wann ein Modell voll spezifiziert ist. Wir können nie wissen, wann wir am Ende der Wissenschaft angekommen sind, weil wir alles vollständig und für immer gültig spezifiziert haben. Es geht bei dieser Überlegung der Spezifikation mehr darum, dass wir die Spezifikation der bestehenden Modelle verbessern. Das kann heissen, dass wir falsche Alltagsvorstellungen korrigieren, indem wir den Kindern irgendwann sagen, dass das bivariate Regressionsmodell mit den Störchen und den Kindern, nicht voll spezifiziert ist und Sex, Verhütung und viele mehr einen gewissen Einfluss hat auf die Geburtenrate. Wir klären aber nicht nur in der Alltagswelt auf, sondern verbessern auch unsere Modelle stetig, indem wir uns fragen, welche Einflussgrössen bei der Erklärung eines Phänomens noch eine Rolle spielen könnten.
Die statistisch, mathematische Anforderung an die Modellspezifikation bedeutet also, dass wir unsere Theorie gut und gründlich entwickeln müssen. Bei einer schlechten Theorie und entsprechend zu wenig erfasster oder einbezogener Modells sind unsere Ergebnisse verzerrt und damit falsch oder mindestens nicht state of the art. Darum muss man immer erst schauen, was der Forschungsstand ist. Der kann repliziert und damit kontrolliert werden, und wenn wir das Modell weiter spezifizieren und neue Ergebnisse erlangen, dann haben wir die Theorie erweitert und einen wissenschaftlichen Mehrwert geschaffen. Es werden auch noch Generationen nach uns und Ihnen kommen, die unsere Theorien überarbeiten und dabei feststellen, dass wir unserer Modelle unterspezifiziert hatten. Das ist dann der wissenschaftliche und zivilisatorische Fortschritt. Wissenschaft wird also nicht irgendwann fertig sein und wichtig bleiben.
2.3.2.3 Keine perfekte oder heftige Multikollinearität (V5.)
Wenn perfekte Multikollinearität vorliegt, dann kann eine Variable perfekt aus den übrigen Variablen vorhergesagt werden (technischer: eine UV ist eine Linearkombination der übrigen UVs). Ein lineares Modell gibt dann keine Antwort auf die ihm gestellte Frage, wenn zwei UVs identisch sind, also untrennbar verwoben. Das liegt daran, dass die Frage an das lineare Modell ist: "Wie starkt ist der Effekt jeder einzelnen UV, wenn die Effekte der übrigen UV herausgerechnet werden?". Wenn eine Variable eine Linearkombination der übrigen Variablen ist, dann bleibt von ihr exakt nichts übrig, wenn die Linearkombination der übrigen Variablen aus ihr herausgerechnet werden. Ist ihre Varianz dadurch 0, ist sie im Grunde eine Konstante, und wie in V1. diskutiert, kann mit Konstanten keine Kovarianz und damit auch kein lineares Modell gerechnet werden. Jedes Statistikprogramm würde also an dieser Stelle aussteigen und ihnen sagen, dass das Modell so nicht gerechnet werden kann, weil perfekte Multikollinearität vorliegt. Das muss also nicht extra getestet werden.
Perfekte Multikollinearität entsteht meistens, wenn eine Variable aus dem Rohdatensatz umkodiert wurde und die Originalvariable und die einfach umkodierte mit im Modell sind. Die schuldige Variable findet man recht schnell. Etwas weniger direkt ersichtlich ist so eine perfekte Multikollinearität durch Datenaufbereitung, wenn ein Index und alle Variablen, aus denen der Index berechnet wurden, mit in das Modell aufgenommen wurden. Wenn Sie also z.B. die Durchschnittsnote im Abi in das Modell packen und alle Noten der einzelnen Fächer auch, die zusammen exakt die Durchschnittsnote ergeben. Suchen Sie in solchen Fällen nach den Indizes. Wenn Sie in dem Beispiel die Durchschnittsnote rausnehmen oder ein paar Fächer, die ihnen für die Erklärung der AV nicht so wichtig erscheinen, dann wird das Problem der perfekten Multikollinearität schnell gelöst sein.
Etwas Multikollinearität ist allerdings nicht nur erlaubt, sondern der Grund dafür, dass wir multivariate Modelle rechnen. Wären die UVs untereinander alle unkorreliert, dann wären alle B's dieselben, wenn nur bivariate Regressionen gerechnet werden würden. In der Formel (2.14) für \(b_2\) sieht man das auch sehr gut: Wenn \(r_{23} = 0\), also keine Multikollinearität beim Modell mit zwei UVs (\(X_2\) und \(X_3\)), dann kommt für \(b_2\) dasselbe raus, wie ohne \(X_3\) (in (2.14) wird $r_{23} = 0 gesetzt und in (2.16) sieht man, dass \(X_3\) oder \(r_3\) keine Rolle spielen).
\[\begin{align} b_2& = \frac{r_{Y2}-r_{23}r_{Y3}}{(1-r_{23}^2)}\frac{S_y}{S_2} \tag{2.14}\\ b_2& = \frac{r_{Y2}-0\cdot r_{Y3}}{(1-0^2)}\frac{S_y}{S_2} \tag{2.15}\\ b_2& = r_{Y2}\frac{S_y}{S_2} \tag{2.16} \end{align}\]
Wenn es etwas Multikollinearität gibt, wird das Produkt aus \(r_{23}r_{Y3}\) aus dem bivariaten \(b_2\) subtrahiert (herausgerechnet). Zusätzlich wird mit einer Korrektur unter dem Bruchstrich von \(1-r^2_{23}\) angepasst. In Worten bedeutet das so viel wie: Wenn wir untersuchen wollen, ob der Storch (UV) die Kinder bringt (AV), aber wissen, dass das auch noch mit Urbanität (\(X_3\)) zusammenhängt, dann müssen wir berücksichtigen (herausrechnen) wie stark Urbanität (\(X_3\)) und Storchenpopulation (\(X_2\)) zusammenhängen (\(r_23\)), wenn bzw. in dem Masse, wie auch die Geburtenrate (Y) mit der Urbanität zusammenhängt (\(r_{Y2}\)). Das steht über dem Bruch der Formel (2.14). Da wir nicht mehr mit den vollen 100% der Varianz von \(X_2\) rechnen können, wird unter dem Bruchstrich der Formel (2.14) auch noch herausgerechnet, um wie viel \(X_2\) durch \(X_3\) beklaut wird (\(1-r^2_{23}\)). Über diesen Teil der Formel lohnt es sich, etwas länger nachzudenken.
Toleranz und VIF
Wenn Multikollinearität bedeutet, dass eine Variable durch eine andere stark bestimmt wird, haben wir für die Bestimmtheit einer Variablen durch andere ein Mass: Das Bestimmtheitsmass \(R^2\). In der Formel (2.14) steht unter dem Bruch ein \(r^2_{23}\), das man besser auch schreiben könnte als \(R^2_{2.3}\), einfach um deutlicher zu machen, dass es um eine multiple Korrelation geht und darum, dass die Regression auf \(X_2\) gemeint ist, von allen übrigen Variablen. Wenn es mehr als nur die \(X_3\) gibt, würden wir in der Formel für \(b_2\) schreiben \(R^2_{2.34567...}\) und bei \(b_3\) \(R^2_{3.24567...}\). Nun ist Multikollinearität nichts Gutes, sondern ein Problem. Darum steht in Formel (2.14) auch \(1-r^2_{23}\). Hier ist also angegeben, wie viel von den 100% Varianz von \(b_2\) übrig bleiben, wenn man herausgerechnet hat, wie stark die übrigen UVs die Variable \(X_2\) bestimmen (\(R^2_{2.34567...}\)). Man könnte auch sagen, dass damit für die Multikollinearität angegeben ist, wie stark ihre Toleranz gegenüber den übrigen Variablen ist. Wenn also zum Beispiel die übrigen Variablen 40% der Variable \(X_2\) erklären, dann wäre die Toleranz \(1-0.4\), also 60%. Diesen Toleranzwert (TOL) sollte man sich bei jeder Regression mit rausgeben lassen, um zu prüfen, wie stark die einzelnen Variablen von Multikollinearität betroffen sind. In Publikationen sieht man diese Werte oft nicht, weil sie von den Forschenden geprüft und für nicht problematisch befunden wurden (wenn diese Forschenden gründlich arbeiten).
Multikollinearität hat vor allem auch eine Bedeutung für die Fehlervarianz der B's, also wie unsicher oder wackelig die b's sind. Darum steckt in der Formel für die \(s_{b_2}^2\) auch das \(1-R_{23}^2\) unter dem Bruchstrich des Faktors drin, der hinten steht. Dieser hintere Faktor ist demnach der Faktor, um den die Fehlervarianz der B's steigt, wenn die Toleranz (\(1-R_{2.3}^2\)) klein ist, weil die jeweilige UV stark durch die übrigen Variablen bestimmt wird (\(R_{2.3}^2\)). Mit diesem Faktor wird auch gearbeitet, indem in Regressionsanalysen in Outputs häufig der Varianz-Inflations-Faktor (VIF) mit angezeigt wird. Wenn also zum Beispiel die Varianz der Variablen \(X_2\) zu 90% durch die übrigen Variablen im Modell aufgeklärt wird, dann ist die Wert TOL nur noch \(1-.9 = .1\). Der Variablen \(X_2\) würden also nur noch 10% seiner Ursprungsvarianz bleiben, um die AV erklären zu können. Das ist nicht viel, worauf eine stabile Regressionsgerade angepasst werden könnte. Darum wackelt das \(b_2\) viel mehr, als wenn die anderen Variablen nicht berücksichtigt worden wären. Die Unsicherheit wurde um den Faktor \(\frac{1}{1-R^2_{2.34567...}}\) inflationiert, also um das Zehnfache! Da muss man sich dann schon fragen, was da eigentlich übrig bleibt.
\[\begin{align} s_{b_2}^2&=\frac{s^2}{n}\cdot\frac{1}{V_2}\cdot\frac{1}{1-R_{2.3}^2} \tag{2.17}\\ s_{b_3}^2&=\frac{s^2}{n}\cdot\frac{1}{V_3}\cdot\frac{1}{1-R_{3.2}^2} \tag{2.18} \end{align}\]
2.3.3 Homoskedastizität (V6.)
Homoskedastizität bedeutet, dass die Streuung der Fehler um die Regressionsgerade überall ungefähr gleich (homo) gross sein sollte. Heteroskedastizität bedeutet, dass die Fehlerstreuung um unsere Regressionsgerade mit der grösse unserer UVs unterschiedlich ist, also z.B. grösser wird, weil Kodierer:innen wenn sie sehr lange nacheinander (weil vielleicht in letzter Minute) kodieren, mit der Zeit immer mehr Fehler machen. Oder weil Kodierer:innen regelmässig ein bisschen kodieren und dabei immer besser werden und immer weniger Fehlerstreuung entsteht. Wenn diese Streuung um die Regressionsgerade mit einer Variablen korreliert wie in Abb. 2.9, dann sind die Standardfehler der b's nicht gut und gültig geschätzt. Mithin sind die t-Werte nicht korrekt, damit die p-Werte und Konfidenzintervalle falsch und schliesslich unsere Entscheidung über die Gültigkeit oder auch die Entscheidbarkeit der Hypothese (H0 oder H1) falsch.
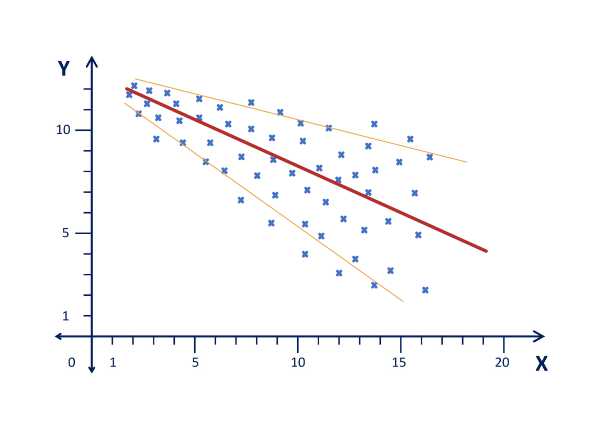
Abbildung 2.9: Heteroskedastizität
Neben diesem breiter oder schmaler werden der Streuung um die Regressionsgerade entsteht Heteroskedastizität oftmals, wenn wir eine Gerade in einen kurvlinearen Zusammenhang einpassen. In der Abb. 2.10 ist gut zu erkennen, dass in (a) die Verteilung der standardisierten Fehler recht gleichmässig ist. In (b) geht eben die Schultüte (bzw. Tüte Marroni) auseinander und stellt damit Heteroskedastizität dar. In (c) kommt die Heteroskedastizität durch eine erzwungene Gerade bei gegebener kurvlinearer Beziehung zwischen den Variablen (das sieht in (b) recht kubisch aus). In (d) wäre es beides zusammen, also ein (vermutlich quadratischer) Zusammenhang, bei dem mit steigendem X auch noch die Streuung steigt.

Abbildung 2.10: Nicht-Linearität der Beziehungen
Lösen kann man die Probleme mit der Heteroskedastizität, indem man GLS rechnet, also (Generalized Least Squares) und dabei zunächst das korrekte b bestimmst, dann die Streuung berechnet und im 2-Stage-Least-Squares mit den gewichteten Residuen rechnen würde. Das zu vermitteln geht über diesen Kurs hinaus. Einfacher ist es mit den kurvilinearen Beziehungen. Die können wir linearisieren. Wir schauen uns also die Verteilung der Residuen an und wenn wir da so eine kurvlineare Beziehung sehen, dann modellieren wir die so, dass sie linear geschätzt werden kann. Das ist gut in Abb. 2.11 abgebildet. Dabei ist nicht entscheidend, dass Sie jetzt schon den Aufbau der Formel verstehen, sondern, dass es komplexere Formeln gibt als die einfache additiv lineare, und durch diese Formeln doch wieder das lineare Modell angewendet werden kann, weil die Formeln für eine "Linearisierung" (Transformation) sorgen.

Abbildung 2.11: Linearisierung kurvlinearer Beziehungen
2.3.4 Verteilung der Residuen (V7. und V8.)
Ein Modell und die zugrundeliegenden Beziehungen ist oft dann gut, wenn die Verteilung der nicht erklärten Varianzanteile sich wie eine einfache Zufallsverteilung verhält bzw. wie Schrott.
2.3.4.1 Normalverteilung der Fehler (V7.)
Die Residuen (also der nicht erklärte Rest bzw. Modellfehler oder einfach Fehler) bezieht sich immer auf die nicht erklärte Streuung in der AV. Wenn wir also unser Modell haben und mit unseren Daten berechnen, dann bekommen wir vorhergesagte Werte und den Rest. Wenn wir den Rest anschauen, dann sollte der nicht zu stark von einer Normalverteilung abweichen.
In der Abb. 2.12 sieht man recht gut, dass links eine relativ gleichmässige Verteilung vorliegt, also kein Zusammenhang zwischen Fehlern und geschätzten Werten zu erkennen ist (Wäre perfekt 0, wenn die rote Linie exakt auf der gestrichelten Null-linie liegen würde.). Im zweiten Fall namens "Case 2" sieht man deutlich, dass es hier eine kuvlineare Abweichung gibt. Hier würde es sich sicher lohnen, ein quadratisches Modell anzupassen.
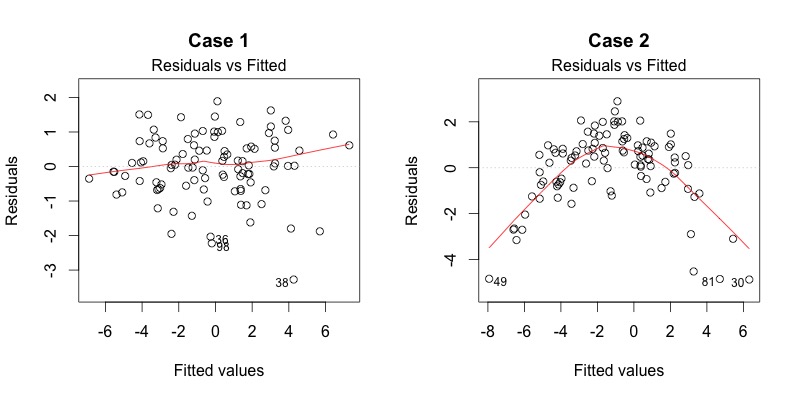
Abbildung 2.12: Residuen gegenüber Modell
In der Grafik 2.13 sind Normal Q-Q-Plots abgebildet. Bei dieser visuellen Darstellung werden die standardisierten Residuen gegen die theoretischen Quantile abgetragen, wobei "theoretisch" hier die zu erwartende Verteilung nach Wahrscheinlichkeitstheorie also nach Normalverteilung. Wenn die Punkte alle auf der Gerade liegen, dann ist der Normalverteilung der Residuen nicht stark widersprochen. Wenn sie, wie im zweiten Fall (typisch Case 2!) abweichen, dann ist die Annahme der Normalverteilung verletzt. Dann würden wir nach einem R-Paket suchen, das mit diesem Problem umgehen kann.
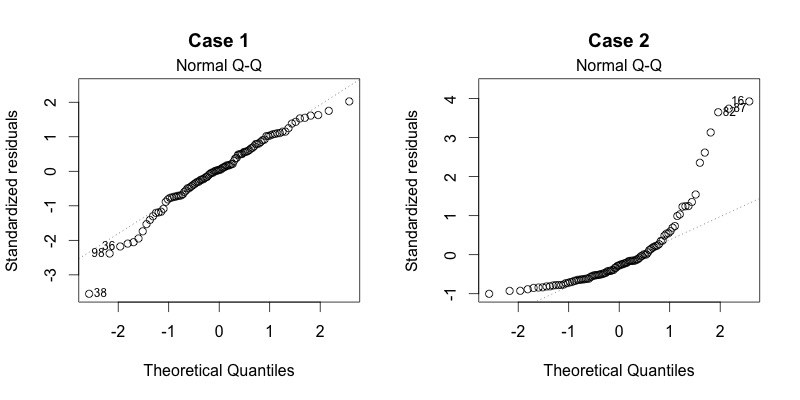
Abbildung 2.13: Normal Q-Q
2.3.4.2 Unabhängigkeit der Fehler (V8.)
Die Unabhängigkeit der Fehler ist eigentlich nur dann ein echtes Problem, wenn die Fehler in eine Reihenfolge gebracht werden können. Das wiederum passiert eher nur bei Zeitreihen, also wenn die Werte einer Erhebung zeitlich angeordnet sind. Dafür gibt es dann allerdings die recht komplexen Zeitreihenanalysen, die eher Statistik IV im Master darstellen. Wir können uns in der R-Übung mal den Durbin-Watson-Test anschauen (zum Spass die Formel (2.19), wo man schon sieht, dass nicht der Index i für Fälle, sondern t durchläuft für time), der prüft, ob die Fehler autokorreliert sind, also hoch mit der um eine Zeiteinheit versetzten Version ihrer selbst korrelieren. Was Sie mitnehmen sollten ist, dass sie bei Erhebungen über die Zeit (Longitudinalstudien), noch prüfen müssen, ob bzw. inwieweit die Fehler miteinander korrelieren.
\[\begin{align} d =& \frac{\sum_{t=2}^T(e_t-e_{t-1})^2}{\sum_{t=1}^T e^2_t} \tag{2.19} \end{align}\]
In einem offiziellen Anmeldeformular, das in Deutschland für Impfungen aufgeschaltet war, stand als dritte Option "Taucher", was der Autor für eine nicht sehr gelungene Übersetzung des Wortes "divers" hält.↩︎
Noch besser ist es, wenn die Geschlechterfrage in Fragebögen halboffen gestaltet ist und die offenen Antworten in Dummys kodiert werden.↩︎
Wenn nur kategoriale Variablen in der oder den UVs stecken, haben wir das, was mal Varianzanalyse genannt wurde.↩︎